
CHƯƠNG II. XÂY DỰNG ONTOLOGY VỚI PROTÉGÉ 4.3 – Tài liệu text
GIỚI THIỆU Ontology là một trong các hình thức biểu diễn tri thức tiên tiến nhất hiện nay. Với hình thức biểu diễn tri thức này, mô hình các khái niệm và quan hệ giữa các khái niệm trong miền tri thức cho phép các tri thức có thể được sử dụng lại cũng như được chia sẻ giữa các ứng dụng. Ontology được ứng dụng rộng rãi trong nhiều lĩnh vực như trí tuệ nhân tạo, truy hồi thông tin… Tuy nhiên, ứng dụng rộng rãi nhất của ontology là trong lĩnh vực web ngữ nghĩa (Semantic Web). Đây chính là nền tảng cung cấp ngữ nghĩa cho dữ liệu, cho phép dữ liệu có thể được hiểu bởi máy tính.
Sơn Giả Đá Cẩm Thạch, Hoa Cương, Thạch Anh – 5 Mẫu Đẹp Cao Cấp Nhất
Do đây là một công nghệ nền tảng của web ngữ nghĩa, nhu cầu xây dựng các ontology là rất lớn. Tạp chí Khoa học Trường Đại học Cần Thơ Số chuyên đề: Công nghệ thông tin (2017): 133-139 134 Tuy nhiên, việc xây dựng các ontology cho một miền tri thức một cách thủ công mất rất nhiều thời gian, đòi hỏi nhiều nhân lực và cần sự hỗ trợ từ các chuyên gia về lĩnh vực đó. Có nhiều nghiên cứu đề xuất các phương pháp để tăng tốc độ và hiệu quả của việc xây dựng ontology (sẽ được giới thiệu trong phần tiếp theo của bài báo).
CHƯƠNG II. XÂY DỰNG ONTOLOGY VỚI PROTÉGÉ 4.3 – Tài liệu text
Ý tưởng cơ bản của các phương pháp này là tự động hoặc bán tự động hoá việc xây dựng các ontology từ các nguồn dữ liệu trong cùng miền tri thức. Trong bài báo này, chúng tôi sẽ đề xuất một phương pháp để xây dựng một ontology gọn nhẹ (lighweight ontology) dựa trên các bảng chú giải (glossary) của miền tri thức tương ứng. Bảng chú giải của một miền tri thức chứa các thuật ngữ, khái niệm (concept) và định nghĩa (definition) cho các thuật ngữ, khái niệm đó. Đây là một nguồn dữ liệu có cấu trúc, vì vậy việc sử dụng các bảng chú giải sẽ dễ dàng hơn so với các nguồn dữ liệu không có cấu trúc. Ngoài ra, các bản chú giải hiện khá phong phú, có sẵn cả dạng ngoại tuyến (offline, ví dụ như sách) lẫn trực tuyến (online, ví dụ như trên các trang web). Do đó, các bảng chú giải có thể được sử dụng như một nguồn dữ liệu chính để xây dựng các ontology. Ngoài ra, để làm phong phú hơn, tăng độ bao phủ của ontology, trong nghiên cứu này, chúng tôi cũng đề xuất sử dụng thêm nguồn cơ sở dữ liệu từ vựng WordNet. Bài báo này được tổ chức như sau: Phần 2 giới thiệu về ontology và các phương pháp xây dựng ontology đã được đề xuất; ở phần 3, chúng tôi mô tả phương pháp xây dựng ontology tự động dựa trên bảng chú giải do chúng tôi đề xuất và thuật toán cụ thể cho phương pháp này; trong phần 4, chúng tôi sẽ trình bày kết quả thực nghiệm trên tập dữ liệu của IMDB; cuối cùng, thảo luận về kết quả đạt được và hướng phát triển sẽ được trình bày trong phần 5. 2 ONTOLOGY VÀ CÁC PHƯƠNG PHÁP XÂY DỰNG ONTOLOGY 2.1 Ontology và các phương pháp thể hiện tri thức Ontology là một đặc tả chính qui (formal) và tường minh (explicit) của các khái niệm được chia sẻ (T. Gruber, 1993). Một ontology có thể được trực quan hóa bằng một đồ thị có hướng với các đỉnh là các khái niệm và các cạnh biểu diễn mối quan hệ giữa các khái niệm. Đây là một trong các hình thức biểu diễn tri thức chính qui rộng rãi nhất, là nền tảng của web ngữ nghĩa (S. Bechhofer, 2009, T. Berners-Lee, 2001).
Dịch vụ dọn nhà theo giờ hải phòng – Dịch vụ vệ sinh nhà ở Hải Phòng
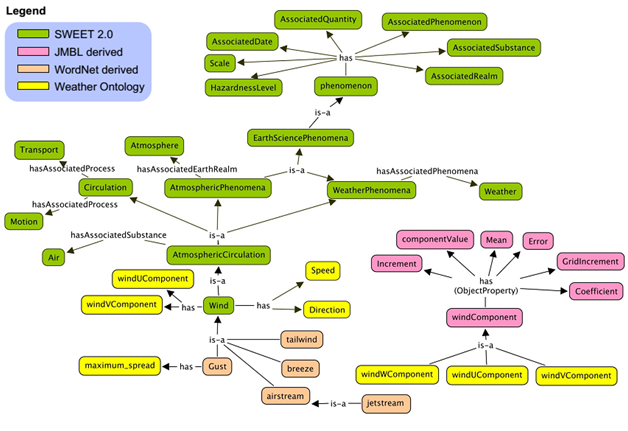
Hình thức biểu diễn tri thức này độc lập với ngôn ngữ tự nhiên và không sử dụng các tri thức liên quan đến từ vựng (lexical) của ngôn ngữ tự nhiên. 0 minh họa một phần của ontology về phim ảnh trong đó có các khái niệm như Award, Movie, Person,… và các mối quan hệ giữa các khái niệm như actedIn, madeBy, producedBy, hasTitle,… Hình 1: Một phần của ontology về phim ảnh được biểu diễn trực quan hóa trong Protégé Vị trí của ontology trong các cấp độ biểu diễn tri thức được mô tả trong 0. Đối với hình thức biểu diễn tri thức bằng các tài liệu (document repository), tri thức được biểu diễn bằng ngôn ngữ tự nhiên và không có yêu cầu hay ràng buộc về cấu trúc (không cấu trúc). Đây có thể được xem là cấp độ biểu diễn tri thức thấp nhất và hình thức biểu diễn tri thức này chỉ có thể được hiểu bởi con người còn máy tính thì không thể “hiểu” và xử lý trực tiếp. Ngược lại, cấp độ biểu diễn tri thức cao nhất là các ontology đầy đủ (heavy-weighted ontology). Cấp độ biểu diễn tri thức này sử dụng các luật logic (logical rule), hay còn gọi là các tiên đề (axioms) để biểu diễn tri thức. Điều này làm cho tri thức được biểu diễn trở nên có cấu trúc và do đó có thể được “hiểu” và xử lý trực tiếp bởi máy tính. Ngoài ra, việc ứng dụng logic trong biểu diễn tri thức còn cho phép thực hiện các suy luận (reasoning) trên tập tri thức này. Các cấp độ biểu diễn tri thức khác như thuật ngữ (terminalogy), bảng chú giải (glossary) và từ điển (thesaurus) được gọi là các hình thức từ vựng được “kiểm soát” (controlled vocabulary). Ví dụ minh họa cho từng cấp độ biểu diễn tri thức có thể được tham khảo trong 0. Hình 2: Các cấp độ biểu diễn tri thức (G. Miller et al., 1990) Tạp chí Khoa học Trường Đại học Cần Thơ Số chuyên đề: Công nghệ thông tin (2017): 133-139 135 2.2 Các phương pháp xây dựng ontology Có hai phương pháp xây dựng ontology là xây dựng thủ công và “học” (tự động, bán tự động). Xây dựng ontology thủ công thường mất nhiều thời gian và đòi hỏi phải có các chuyên gia trong lĩnh vực đó. Do đó, phương pháp này chỉ phù hợp để xây dựng các ontology cho các miền tri thức nhỏ, giới hạn và ít thay đổi. Đối với các ontology lớn hay thường thay đổi thì cần có phương pháp khả thi hơn, tiết kiệm thời gian, nhân lực và đáp ứng với các thay đổi tốt hơn, đó chính là phương pháp xây dựng một cách tự động hay bán tự động hay còn gọi là “học” ontology (ontology learning). Học ontologgy là quá trình xác định các thuật ngữ (term), các khái niệm (concept), các quan hệ phân loại hay cấp bậc (taxonomy relation) và quan hệ không cấp bậc (non-taxonomy relation), các tiên đề (axiom). Đây chính là các thành phần của một ontology. Tuy nhiên, tùy vào từng cấp độ chi tiết, vào qui mô của ontology mà quá trình học có thể chỉ xác định một số trong các thành phần trên. Vị trí của các thành phần trên trong một ontology được gọi là “Ontology Learning Layer Cake” và được mô tả trong 0. Hình 3: Ontology Learning Layer Cake (S. Bird et al., 2008) Việc học các thành phần trong Ontology Learning Layer Cake càng lên cao càng phức tạp. Ở mức độ thấp nhất là các thuật ngữ, là thành phần cơ bản nhất của ontology. Một thuật ngữ có thể là một từ đơn, từ kép,… mô tả cho tri thức trong một lĩnh vực cụ thể.
Ví dụ, một số thuật ngữ trong lĩnh vực y tế như “bệnh viện” (hopital), “bệnh” (disease, illness), “thuốc” (medicine),… Đồng nghĩa là một nhóm các thuật ngữ có cùng nghĩa với nhau, ví dụ {disease, illness}. Khái niệm là các thuật ngữ có gán nhãn và các khái niệm đồng nghĩa của nó. Mức kế tiếp của việc xây dựng ontology là xác định các quan hệ giữa các khái niệm. Quan hệ cấp bậc là quan hệ “là” (is-a), được dùng để xây dựng cây phân cấp khái niệm (hierarchy). Ví dụ, một “bác sĩ” (Doctor) là một “con người” (Person). Còn loại quan hệ không cấp bậc là các quan hệ giữa các khái niệm ngoài quan hệ cấp bậc. Ví dụ, quan hệ “chữa bệnh” (cure) là quan hệ không cấp bậc giữa “bác sĩ” và “bệnh nhân”. Quan hệ cấp bậc thường dễ xác định hơn quan hệ không cấp bậc vì nó có thể được nhận dạng dễ dàng hơn. Ngược lại, quan hệ không cấp bậc thì thường khó xác định hơn vì mối quan hệ này thường là không tường minh và đa dạng hơn. Ở mức độ cao nhất của Ontology Learning Layer Cake là các luật logic hay tiên đề. Các luật logic này được định nghĩa trên các khái niệm và quan hệ giữa các khái niệm. Chúng được dùng mô tả những ràng buộc phức tạp trên các khái niệm hoặc các quan hệ. Các ràng buộc này cho phép kiểm tra tính đúng đắn của ontology cũng như giảm kích thước (số lượng các thành phần) của ontology vì một số thành phần không cần khai báo tường minh trong ontology mà có thể được suy luận từ các luật này. Một ví dụ về luật logic trong ontology là: ∀ݔ ,ݕሺcướiሺݔ ,ݕሻ → yêuሺݔ ,ݕሻ (với hai người bất kỳ x, y nếu x cưới y thì có nghĩa là x yêu y). Như vậy, giả sử trong ontology đã chứa tri thức cướiሺݔ ,ݕሻ thì ta có thể suy luận ra là x và y yêu nhau mà không cần phải thêm tri thức này vào ontology. Hầu hết các nghiên cứu hiện tại sử dụng tập ngữ liệu (text corpus) của miền tri thức kết hợp với các kỹ thuật như máy học hoặc các kỹ thuật trong xử lý ngôn ngữ tự nhiên,… để xây dựng hay học onlology. Các phương pháp này có thể được phân làm 3 loại: phương pháp dựa trên thống kê (statistic-based), phương pháp dựa trên logic và phương pháp dựa trên xử lý ngôn ngữ tự nhiên. Một số nghiên cứu cụ thể kết hợp nhiều phương pháp lại với nhau. Wong et al. (2012) đã thực hiện một nghiên cứu tổng quan về các phương pháp xây dựng ontology tự động.
Mua Bán Nhà Đất Huyện Củ Chi Giá Rẻ Tháng 10/2021
Trong các phương pháp xây dựng ontology tự động trên, phương pháp dựa trên thống kê và ngôn ngữ tự nhiên được sử dụng rộng rãi hơn phương pháp dựa trên logic. Phương pháp dựa trên thống kê dựa vào 1 tiên đề là các từ xuất hiện cùng nhau của các từ vựng thường có nghĩa là chúng có mối liên hệ với nhau. Phân cụm (clustering) là 1 kỹ thuật phổ biến dùng để phân các thuật ngữ vào các nhóm dựa vào độ đo tương đồng (similarity measure) (K. Linden and J. Piitulainen, 2004). Trong nghiên cứu của H. Fotzo và P. Gallinari (2004), các tác giả đề xuất một phương pháp để xây dựng mối quan hệ phân cấp bằng cách sử dụng xác suất có điều kiện của sự xuất hiện thuật ngữ trong tài liệu. Cho hai thuật ngữ x và y, nếu ܲሺݔ|ݕሻ ൏ ܲሺݕ|ݔሻ và ܲሺݔ|ݕሻ ݐ với t là một ngưỡng cho trước, ܲሺݔ|ݕሻ là xác suất xuất hiện thuật ngữ x khi có thuật ngữ y thì x và y có quan hệ với nhau. Một phương pháp dựa trên thống kê nữa là sử dụng độ đo TF-IDF để đo tần suất xuất hiện của thuật ngữ trong các tập ngữ liệu với qui mô khác nhau (các tập ngữ liệu chung, các tập ngữ liệu trong một miền tri thức cụ thể,…) (G. Salton and Tạp chí Khoa học Trường Đại học Cần Thơ Số chuyên đề: Công nghệ thông tin (2017): 133-139 136 C. Buckley, 1988). Các thuật ngữ có quan hệ với nhau thường xuất hiện cùng nhau trên nhiều tập ngữ liệu khác nhau. Hạn chế của phương pháp dự trên thống kê là không ứng dụng được ngữ nghĩa cũng như các đặc điểm của ngôn ngữ trong quá trình xây dựng ontology. Phương pháp xây dựng ontology tự động dựa trên các kỹ thuật xử lý ngôn ngữ tự nhiên được áp dụng rộng rãi hơn cả vì nó có thể khắc phục những hạn chế của phương pháp dựa trên thống kê. Ngoài ra, phương pháp này còn vận dụng được các công cụ xử lý ngôn ngữ tự nhiên rất mạnh đã được phát triển. Ví dụ như TreeTagger (G. Salton and C. Buckley, 1988) và Link Grammar Parser (D. Temperley and D. Sleator, 1993) là các công cụ gán nhãn từ loại (POS tagging) và phân tích ngữ pháp rất mạnh. Hoặc NLTK (Natural Language Toolkit) là một bộ công cụ toàn diện cho các tác vụ xử lý ngôn ngữ tự nhiên. Phân tích cú pháp câu có thể giúp xác định các thuật ngữ cũng như các quan hệ giữa các khái niệm. Ví dụ, kết quả một phân tích cấu trúc “thuật ngữ” – “động từ” – “thuật ngữ” thì “động từ” có thể được coi là một ứng cử viên cho một quan hệ. Các cơ sở dữ liệu từ vựng (lexical database) như WordNet (G. Miller et al., 1990) cũng rất hữu ích để tìm kiếm các khái niệm và quan hệ đã được định nghĩa trước (synonym, hyponym, hypernym, meronym,…) (W. Zhou et al., 2006). Mặc dù tập ngữ liệu (text corpus) vẫn được sử dụng như là nguồn tài nguyên chính bởi đa số các phương pháp xây dựng ontology tự động, có nhiều nghiên cứu đang đề xuất việc sử dụng các nguồn dữ liệu có cấu trúc để xây dựng hoặc “làm giàu” ontology. Ví dụ, Wikipedia, một trong những cơ sở tri thức trực tuyến lớn nhất, là một nguồn tài nguyên có giá trị để trích xuất quan hệ giữa các thuật ngữ. Liu et al. (2008) đã sử dụng hệ thống phân loại của Wikipedia và hộp thông tin trên hệ thống này để trích xuất các bộ ba (tripple, ví dụ ), dùng để xây dựng ontology. Ngoài ra, cũng có một số nghiên cứu sử dụng bảng chú giải để xây dựng ontology (J. Hilera et al., 2010; M. Li et al., 2005) hoặc “làm giàu” ontology đã có sẵn (R. Navigli and P. Verladi, 2008). Tuy nhiên, trong các nghiên cứu này thì chỉ sử dụng duy nhất nguồn dữ liệu là ontology nên ontology tạo được còn hạn chế. 3 XÂY DỰNG ONTOLOGY DỰA TRÊN BẢNG CHÚ GIẢI Trong phần này, chúng tôi sẽ đề xuất một phương pháp xây dựng ontology gọn nhẹ dựa trên bảng chú giải. Bảng chú giải là một danh sách các khái niệm và định nghĩa của khái niệm đó. Ví dụ, dưới đây là một số mục trong bảng chú giải của IMDB (The Internet Movie Database): Agent A person responsible for the professional business dealings of an actor, director, or other artist. An agent typically negotiates the contracts on behalf of the actor or director, and often has some part in selecting or recommending roles for their client. Art Director The person who oversees the artists and craftspeople who build the sets. See also production designer, set designer, set director, leadman, and swing gang. Trong ví dụ trên, “Agent” và “Art director” là các khái niệm và “A person responsible for…” và “The person who oversee…” là định nghĩa tương ứng cho các khái niệm này. Do đó, mỗi khái niệm trong bảng chú giải chính là một khái niệm trong ontology. Việc xác định các khái niệm này khá dễ dàng. Như vậy, trọng tâm của phương pháp xây dựng ontology tự động là xác định mối quan hệ giữa các khái niệm. Ngoài ra, xác định các khái niệm mở rộng trong bảng chú giải cũng đòi hỏi sử dụng các kỹ thuật trong xử lý ngôn ngữ tự nhiên hoặc máy học. Trong nghiên cứu này, chúng tôi đề xuất sử dụng các biểu thức chính quy (regular expression) kết hợp với các kỹ thuật phân tích ngữ pháp POS tagger trong xử lý ngôn ngữ tự nhiên để tìm ra các khái niệm mở rộng cũng như các quan hệ giữa các khái niệm. Mô hình xây dựng ontology tự động được trình bày trong 0. Hình 4: Mô hình xây dựng ontology tự động từ bảng chú giải 3.1 Biểu thức chính quy Bảng chú giải thường chứa các tham chiếu chéo (cross-references) giữa các khái niệm. Do đó, các biểu thức chính quy sẽ rất hữu ích trong việc tự động nhận dạng và phân loại các quan hệ. Một số tham chiếu chéo như: “contrast with” hoặc “disjoint with”: thể hiện quan hệ trái nghĩa giữa hai khái niệm. Ví dụ: arcade: A series of arches supported by columns or piers. Contrast with colonnade Tạp chí Khoa học Trường Đại học Cần Thơ Số chuyên đề: Công nghệ thông tin (2017): 133-139 137 “synonym”, “as known as”, “to be known as” hoặc “see”: thể hiện quan hệ đồng nghĩa giữa các khái niệm. barrel vault, also known as a tunnel vaultor: an architectural element formed by the extrusion of a single curve along a given distance “see also”: thể hiện các khái niệm có liên quan với nhau. anamorphic: An optical system which has different magnifications in the vertical and horizontal dimensions of the picture. See also aspect ratio, contrast with spherical. “sub class of”: thể hiện mối quan hệ đặc trưng hóa. (quan hệ cha-con giữa các khái niệm). eutherians: a subclass of mammals which give birth to well-developed young. Humans are part of this subclass. Ngoài ra, một số mẫu cú pháp ngôn ngữ khác cũng rất hữu ích trong việc xác định các quan hệ giữa các khái niệm. Ví dụ, “concept1 such as concepts2” ngụ ý rằng concept2 là 1 khái niệm con của concept1. Do đó, bằng cách sử dụng các quan hệ đơn giản này giữa các khái niệm, cho phép xác định nhiều quan hệ trong ontology. 3.2 WordNet WordNet là một cơ sở dữ liệu từ vựng lớn nhất của tiếng Anh, được sử dụng như là một nguồn tài nguyên quan trọng trong rất nhiều ứng dụng về xử lý ngôn ngữ tự nhiên và trong các lĩnh vực khác có liên quan. WordNet cho phép ta truy xuất một cách dễ dàng đến các khái niệm và một tập quan hệ rất phong phú giữa các khái niệm như synonyms, hyponymy, hypernymy, meronym,… Do đó, cho một cặp khái niệm, ta có thể kiểm tra xem một mối quan hệ nào đó có tồn tại giữa chúng hay không. Nói cách khác, cho một khái niệm C, nếu một khái niệm C’ nằm trong tập hypernym hoặc meronym của C, hoặc các quan hệ ngữ nghĩa khác thì ta có thể thêm mối quan hệ tương ứng vào ontology. 3.3 Link Grammar Quan sát cú pháp của một câu, ta có thể dễ dàng thấy được nếu hai khái niệm xuất hiện trong cùng một câu thì động từ liên kết hai khái niệm này thường thể hiện cho quan hệ giữa hai khái niệm. Để thực hiện phân tích câu và tìm động từ thể hiện mối quan hệ giữa các khái niệm, chúng ta cần phải phân tích cú pháp (syntatic) và phụ thuộc (dependency). Trong nghiên cứu này, chúng tôi đề xuất sử dụng Link Grammar (D. Temperley and D. Sleator, 1993), một trong những kỹ thuật sử dụng rộng rãi nhất cho việc phân tích cú pháp câu. Link Grammar không chỉ tạo ra cây cú pháp như POS tagger mà còn cung cấp thông tin về sự phụ thuộc giữa các cặp từ trong câu dưới dạng liên kết (quan hệ). Trong nghiên cứu này, chúng tôi sử dụng PTQL (L. Tari et al., 2010) thay sử dụng trực tiếp Link Grammar. Ngoài việc hỗ trợ xây dựng cây cú pháp và các liên kết, PTQL còn hỗ trợ lưu trữ các thông tin này vào cơ sở dữ liệu quan hệ và ngôn ngữ truy vấn để chúng ta có thể thao tác (sửa đổi, bổ sung, truy vấn) dữ liệu một cách dễ dàng. 3.4 Giải thuật xây dựng ontology tự động từ bảng chú giải Giải thuật xây dựng ontology tự động từ bảng chú giải được mô tả bằng mã giả (pseudo code) trong Giải thuật 1.
– Protégé tự động lưu một bản tạm của Ontology. Nếu có lỗi phát sinh trong
quá trình thao tác thì Ontology cũ sẽ tự động được phục hồi. Người thiết kế cũng có
Sơn Maxilite Trong Nhà Total – Mã Màu Xanh Lá Nhạt 73260 ( Greenville) Bình Minh
thể chuyển qua lại giữa hai bản Ontology này bằng chức năng Revert to a Previous
Version và Active Current Version.
– Cung cấp chức năng tìm kiếm lỗi, kiểm tra tính nhất quán và đầy đủ của
Ontology. Để sử dụng, người thiết kế chọn chức năng Run Ontology Test và Check
Consistency.
– Cho phép các lớp và thuộc tính của Ontology này có thể được sử dụng trong
một Namespace khác mà chỉ cần sử dụng các URL để tham khảo. Để sử dụng, chọn
chức năng Move Resource to Namespace.
– Hỗ trợ suy luận trực tiếp trên Ontology dựa trên Interface chuẩn DL
Implementation Group (DIG).
– Hỗ trợ sinh mã tự động. Protégé cho phép chuyển Ontology thành mã nguồn
RDF/XML, OWL, DIG, Java, EMF Java Interfaces, Java Schema Classes.. Các mã
này có thể được nhúng trực tiếp vào ứng dụng và là đầu vào cho các thao tác trên
Ontology khi cần.
– Cung cấp đầy đủ chuẩn giao tiếp cho các Plug-in.
Tuy nhiên, Protégé cũng thể hiện một số hạn chế như không cho phép truy
vấn từng phần một cơ sở tri thức dẫn tới việc không quản lý hiệu quả các cơ sở tri
thức có kích thước lớn, hoặc chưa hỗ trợ kết nối trực tiếp với một số hệ quản trị cơ
sở tri thức phổ biến như Sesame…
Một Ontology mô tả các khái niệm và các quan hệ quan trọng trong một miền
cụ thể, cung cấp các từ vựng cho miền đó cũng như là một đặc tả máy tính của ý
nghĩa của các thuật ngữ được sử dụng trong các từ vựng. Phạm vi của các Ontology
từ các phân lớp và phân loại, các lược đồ cơ sở dữ liệu đển các lý thuyết đầy đủ.
Trong những năm gần đây, các Ontology được chấp nhận trong rất nhiều công việc
và các cộng đồng khoa học để chia sẻ, sử dụng lại và xử lý tri thức miền. Ontology
là trung tâm của rất nhiều ứng dụng như cổng thông tin tri thức khoa học, các hệ
13
thống tích hợp và quản lý thông tin, thương mại điện tử và các dịch vụ web ngữ
nghĩa.
Nền tảng Protégé hỗ trợ hai công cụ để xây dựng mô hình Ontology.
Trình soạn thảo Protégé-Frame cho phép người sử dụng xây dựng và lưu trữ
các Ontology dưới dạng khung theo giao thức kết nối dựa trên tri thức mở. Trong
mô hình này một Ontology bao gồm một tập các lớp được tổ chức trong một hệ
thống tổng hợp để biểu diễn các khái niệm, một tập các slot liên quan đến lớp mô tả
các thuộc tính và các mối quan hệ, và một tập các thể hiện của các lớp này. Các thể
hiện của các khái niệm lưu giữ các giá trị cụ thể trong các thuộc tính của nó.
Trình soạn thảo Protégé-OWL cho phép người sử dụng xây dựng các
Dịch vụ dọn xác nhà giá rẻ hơn thị trường từ 15-20% | Musk.vn
Ontology cho Web ngữ nghĩa, cụ thể trong ngôn ngữ Ontology Web. Một Ontology
có thể bao gồm các mô tả của các lớp, các thuộc tính và các thể hiện của nó. Từ một
Ontology, các ngữ nghĩa chuẩn OWL mô tả làm thế nào hướng các kết quả logic
của nó, không những các sự kiện được biểu diễn trong ontology mà còn được kế
thừa bới các ngữ nghĩa. Sự kế thừa có thể được dựa trên một tài liệu đơn hoặc nhiều
tài liệu phân tán đã được kết hợp bởi định nghĩa bằng các kỹ thuật OWL.
2. Các thành phần của bản thể học OWL
OWL bản thể học có thành phần tương tự như Protégé bản thể học dựa trên
khung. Tuy nhiên, các thuật ngữ dùng để mô tả các thành phần này là hơi khác nhau
từ đó được sử dụng trong Protégé. Một Ontology OWL bao gồm cá nhân, Properties,
và lớp học, có khoảng tương ứng với Protégé Instances, Slots và lớp học.
2.1. Các đối tương cho Ontology
Các mô tả đối tượng
– Lớp tương đương (Equivalent classes)
– Lớp cha (superclass)
14
– Lớp kế thừa
– Thành viên
– Khóa
2.2. Thuộc tính (Properties)
Thể hiện quan hệ nhị phân của các thực thể (quan hệ giữa hai thực thể) như
liên kết hai thực thể với nhau
– Ví dụ thuộc tính “do_virus” liên kết hai thực thể “cúm_gà” và “H5N1”
Thuộc tính có có khả năng đảo ngược với nhau, ví dụ thuộc tính “isBaseOf”
có đảo ngược là “hasBase”
Các mô tả về thuộc tính:
15
– Functional: Quan hệ dạng hàm. Ví dụ: thuộc tính hasMother có tính chất
functinal
– Inverse Functional: Thuộc tính đảo. Ví dụ: hasAuthor có thuộc tính inverse
là writtenBy
– Transitive: Quan hệ bắc cầu
– Symmetric: Quan hệ đối xứng. Ví dụ thuộc tính hasSibling là đối xứng.
– Asymetric: Bất đối xứng
– Reflexive: Phản xạ. Ví dụ thuộc tính knows là phàn xạ chẳng hạn như Peter
knowsPeter
himself.
– Irreflexive: Không phản xạ
Hình : Minh họa về thuộc tính Protégé
16
2.3. Lớp (Classes)
Lớp OWL là một bộ những thực thể, các thực thể được mô tả logic để định
nghĩa các đối tượng của lớp
Lớp được xây dựng theo cấu trúc phân cấp cha-con như là một sự phân loại
các đối tượng
Ví dụ
Động vật là lớp cha của bò sát, bò, kiến…
4. Các bước xây dựng Ontology với Protégé
– Xác định Domain
– Liệt kê, xác định các concept
– Định nghĩa lớp, phân cấp lớp
– Xác định thuộc tính và các Restriction
– Tạo các thực thể
4.1. Xác định Domain
Kiểu phụ thuộc của Ontology, phạm vi Ontology, những người sử dụng sẽ
phát triển mô hình. Những thông tin hữu ích Ontology có thể cung cấp.
4.2. Liệt kê, xác định các concept
Xác định các thuật ngữ liên quan, chúng có thể được thay đổi và mở rộng
thêm. Xác định thuộc tính liên quan đến các thuật ngữ đó.
– Ví dụ các thuật ngữ liên quan đến con người có thế là nam, nữ, họ, tên…
17
4.3. Định nghĩa lớp, phân cấp lớp
Xác định các lớp và các lớp con của nó
Sự phân cấp các lớp dựa vào các giác quan, sự nhận thức và những sự thật
hiển nhiên.
– Ví dụ động vật sẽ có các lớp con là bò sát, thú…
4.4. Xác định thuộc tính và các Restriction
Xây dựng các thuộc tính để có thể mô tả cụ thể lớp và phân cấp lớp
– Lấy ví dụ thuộc tính con người là tên, tuổi, quê quán, ngày sinh…
Thêm vào thuộc tính các Restriction (giới hạn). Có thể thêm vào thuộc tính
quê quán Restriction là lớp tỉnh; lớp con người có thể tạo các thực thể có quê quán
trong lớp tỉnh.
4.5. Tạo các thực thể
Chèn thêm các thực thể cho lớp để làm rõ các lớp và thuộc tính của lớp đã tạo.
Ví dụ lớp con người có thực thể: Ngân, Lan, Hương, Nam…
5. Xây dựng một Ontology với Protégé
– Khởi động chương trình Protégé.
– Tạo lớp Class .
– Tạo các lớp con của lớp .
– Tạo các thuộc tính Properties.
– Tạo các thực thể của lớp .
– Tiến hành sinh luật và truy vấn.
18
5.1. Khởi động chương trình Protégé:
`
Hình : Màn hình khởi dộng của Protégé
5.2. Tạo lớp Class :
B1 : Click chọn Tab Classes (1)
B2 : Click chọn (2)
B3 : Đặt tên cho lớp ” ” (3)
19
Hình 8 Các bước tạo lớp trong Protégé
5.3. Tạo các lớp con
B1 : Click chọn lớp “WineDescription” vừa tạo (1)
B2 : Click chọn (2) để tạo lớp
B3 : Đặt tên các lớp con của lớp ” WineDescription ”
Ta sẽ được các lớp con của lớp ” WineDescription ” vừa tạo là Wincolor,
WinTaste.
B4 : Phân cấp lớp nếu có (3) (4)
20
Hình : Các bước tạo lớp con trong Protégé
5.4. Tạo các thuộc tính Properties
– Chọn tab Properties (1) rồi chọn (2)
– Chọn Add Sub property (3)
– Đặt tên thuộc tính (4)
– Chọn các đặc tả và mô tả cho thuộc tính nếu có như Funtional, Transitive,
Domains, Ranges….
21
22
Hình : Các bước tạo thuộc tính trong Protégé
5.5. Sơ đồ Ontology
– Chọn Tap OntoGaf (1).
– Chọn lớp muốn xem (2).
– Chọn các chế độ hiển thị (3).
23
[external_footer]










